Recommender Systems for Last.fm
Recommender systems with collaborative filtering created with Apache Mahout framework. The system uses a Music Recommendation dataset for research purposes as input, but you can train it and predict recommendations with any other dataset. This project explores the calibration and accuracy of user-based and item-based models.
Data
The original dataset contains <user, timestamp, artist, song> tuples collected from Last.fm API, using the user.getRecentTracks() method. This dataset represents the whole listening habits (till May, 5th 2009) for nearly 1,000 users.
The pre-processed dataset below contains <user, artist, rating> tuples. The rating field was calculated by normalizing the number of times a user listened to a specific artist’s songs in Last.fm.
Table format: u.data.csv
| user id | artist id | rating |
|---|---|---|
| 1 | 100001 | 5.0 |
| 3 | 101943 | 4.6 |
| 6 | 100906 | 4.3 |
| 11 | 101722 | 3.6 |
| 15 | 107070 | 3.9 |
You can see the original dataset here
Model Tuning
- The training results of the user-based collaborative filtering model are shown below:
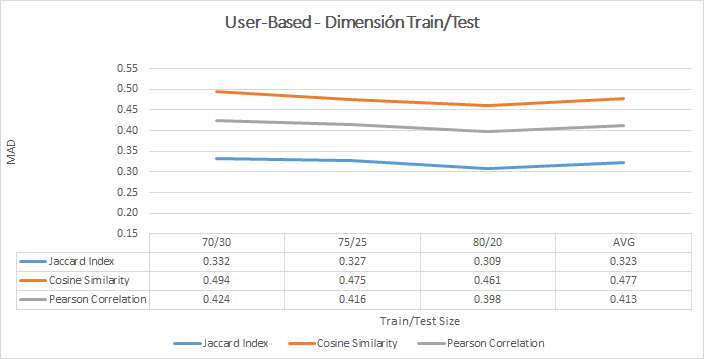
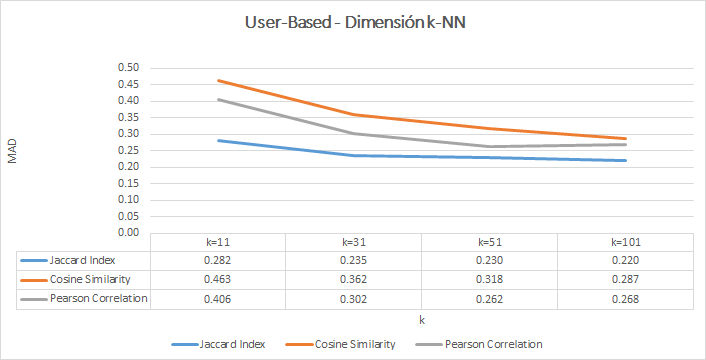
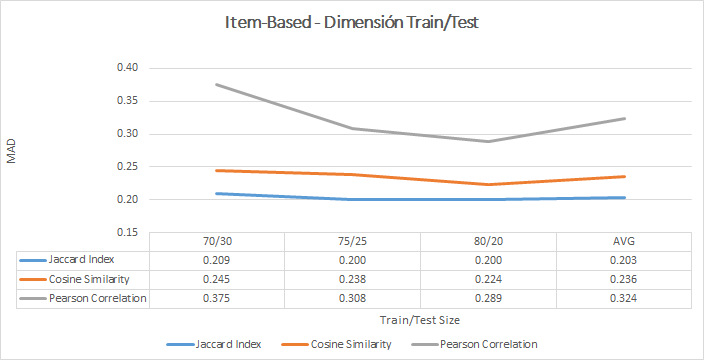
- The training results of the item-based collaborative filtering model are shown below:
Technologies and Techniques
- Java (JDK 1.7)
- Eclipse IDE
- Apache Mahout
- Maven dependencies
Program Execution Rules
The project has an executable in the ‘jar’ folder. The JAR name is: RS_CF_LastFm-v1.jar and you must send as input parameters:
- User ID for which recommendations are to be computed
- Filepath to the input data
- Filepath to the output file
- Type of collaborative filtering: USER or ITEM
- Similarity metric: COSINE, PEARSON or JACCARD
- Number of neighbors for the KNN algorithm (only applies with user-based filtering). Default value: 51
- Desired number of recommendations. Default value: 10
Execution examples:
java -jar RS_CF_LastFm-v1.jar 1 ../data/in/u.data.csv ../data/out/output.txt USER COSINE 101 20
java -jar RS_CF_LastFm-v1.jar 10 ../data/in/u.data.csv ../data/out/output.txt ITEM PEARSON 0 10
java -jar RS_CF_LastFm-v1.jar 10 ../data/in/u.data.csv ../data/out/output.txt ITEM JACCARD
The .JAR program must be run with Java 7 or higher.
Program Output
Once trained the model, the system can make recommendations (on demand) for users, as follows:
| user id | artist id | rating |
|---|---|---|
| 1 | 130710 | 4.366509 |
| 1 | 114674 | 3.0061495 |
| 1 | 143895 | 2.9370918 |
| 1 | 103116 | 2.8950827 |
| 1 | 104052 | 2.7250140 |
| 1 | 135747 | 2.6153402 |
| 1 | 135743 | 2.5869453 |
| 1 | 102936 | 2.5726979 |
| 1 | 113273 | 2.5512722 |
| 1 | 114145 | 2.5447776 |
Conclusions
- Apache Mahout is an excellent fast development framework for Recommender Systems projects. It has a wide variety of Machine Learning algorithms to make predictions (recommendations) and an extensive list of similarity functions.
- In static or semi-static scenarios, recommendation systems with items-based collaborative filtering offer better results than those users-based , since it is easier to calculate the similarity between items than between users.
- As a general rule, both in the user-based and in the item-based models, the predictive results improved when the models were exposed to more data (75/25 or 80/20), since the Machine Learning algorithm used has more information from which to learn.
- The construction of a model items-based takes more time than the construction of a user-based model. However, once the model is built, it makes predictions more quickly and above all, more accurately than the user-based one.
- When a new user is created, the user-based recommender model will have a cold start for that user, until the user performs enough interactions to be able to look like someone else. Analogously, it occurs for the item-based model when a new item is created.
Contributing and Feedback
Any kind of feedback/criticism would be greatly appreciated (algorithm design, documentation, improvement ideas, spelling mistakes, etc…).
Authors
- Created by Andrés Segura Tinoco and Francisco Ariza Benavides
- Created on May 29, 2019
License
This project is licensed under the terms of the MIT license.
Acknowledgements:
Thanks to Last.fm for providing the access to this data via their web services.