Text Processing: CiteSeer UMD
Program that preprocesses a collection of documents to calculate the frequency of the most common terms and identify the keywords of each document. The first time (Q2) will do it without using the stemming technique and without removing the stopwords. The second time (Q3) will use these techniques. The Approach is: First remove the stop-words and then stemming. After stemming, if the resulting word is a stop word then will be remove it.
The project name is: HW1_TextProcess and it was created using the Eclipse IDE. The program solves all the questions in a single execution (run).
Data
The CiteSeer UMD collection is a standard text document collection, consisting of abstracts of research articles from Computer Science, which are sampled from the CiteSeer digital library.
Algorithms
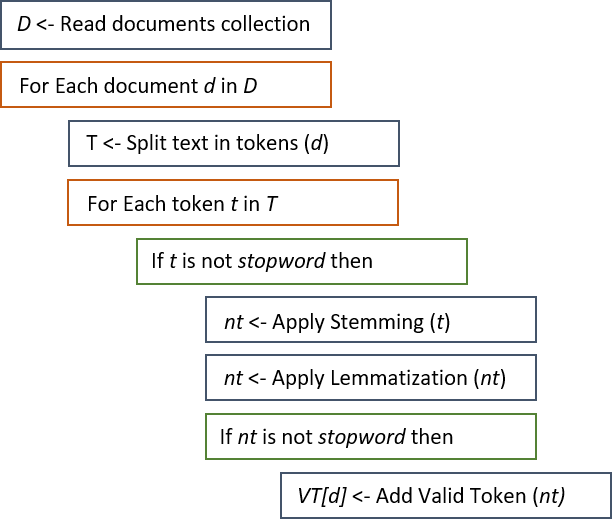
Technologies and Techniques
- Java (JDK 1.7)
- Eclipse IDE
- TF-IDF
- Tokenization
- Stemming
- Lemmatization
- Remove stop-words
Program Execution Rules
The project has an executable in the ‘jar’ folder. The JAR name is: KD_HW1_v1.7.jar and you must send the path of the “citeseer” directory as a parameter.
Therefore, to run the program you should go into the jar directory on your machine and then execute the following command:
cd jar_folder
java -jar KD_HW1_v1.7.jar citeseer/
The .JAR program must be run with Java 7 or higher.
Program Output
The program will show by console the answers for the project questions.
In the “output” directory the following 3 files will be created:
- output/filelist.txt: The file contains the list of used files.
- output/wordlist.txt: The file contains the list of unique words (vocabulary).
- output/sparse-tf-idf.txt: The file contains the sparse TF-IDF representation. Files “filelist.txt” and “wordlist.txt” should be used to use the sparse TF-IDF index.
The “output” folder must exist and be in the same directory as the data folder.
Project Questions/Answers
Q1: Write a program that preprocesses the collection. In doing so, tokenize on whitespace and remove punctuation:
The 3,186 files were loaded correctly from: citeseer/ folder.
Q2: Determine the frequency of occurrence for all the words in the collection:
a. Total number of words: 472,080
b. Vocabulary size: 19,126
c. Top 20 words in the ranking (i.e., the words with the highest frequencies):
| # | Word | Total Freq | Absolute Freq (%) |
|---|---|---|---|
| 1 | the | 25,662 | 5.435943060498221 |
| 2 | of | 18,640 | 3.948483307913913 |
| 3 | and | 14,131 | 2.9933485849855956 |
| 4 | a | 13,364 | 2.8308761226910693 |
| 5 | to | 11,536 | 2.4436536180308424 |
| 6 | in | 10,067 | 2.1324775461786136 |
| 7 | for | 7,379 | 1.5630825283850196 |
| 8 | is | 6,578 | 1.393407896966616 |
| 9 | we | 5,138 | 1.0883748517200476 |
| 10 | that | 4,820 | 1.0210133875614302 |
| 11 | this | 4,446 | 0.9417895271987798 |
| 12 | are | 3,737 | 0.7916031181155736 |
| 13 | on | 3,656 | 0.7744450093204541 |
| 14 | an | 3,281 | 0.6950093204541603 |
| 15 | with | 3,200 | 0.6778512116590408 |
| 16 | as | 3,057 | 0.6475597356380275 |
| 17 | by | 2,765 | 0.58570581257414 |
| 18 | data | 2,691 | 0.5700305033045246 |
| 19 | be | 2,500 | 0.5295712591086257 |
| 20 | information | 2,322 | 0.4918657854600915 |
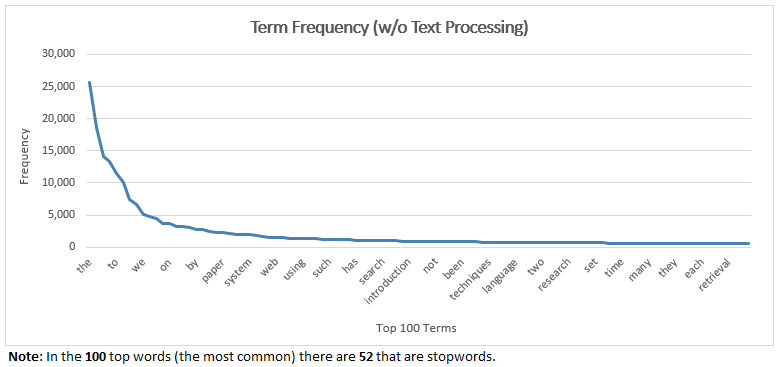
d. List of stop-words contained in the top 20 words: The top 20 words (most common) that are stopwords is 18.
The word(1) 'the' is a stop-word.
The word(2) 'of' is a stop-word.
The word(3) 'and' is a stop-word.
The word(4) 'a' is a stop-word.
The word(5) 'to' is a stop-word.
The word(6) 'in' is a stop-word.
The word(7) 'for' is a stop-word.
The word(8) 'is' is a stop-word.
The word(9) 'we' is a stop-word.
The word(10) 'that' is a stop-word.
The word(11) 'this' is a stop-word.
The word(12) 'are' is a stop-word.
The word(13) 'on' is a stop-word.
The word(14) 'an' is a stop-word.
The word(15) 'with' is a stop-word.
The word(16) 'as' is a stop-word.
The word(17) 'by' is a stop-word.
The word(19) 'be' is a stop-word.
e. The minimum number of unique words accounting for 15% is: 4 which represent the 15.208651076088799 % of the total number of words in the collection.
Q3: Integrate the Porter stemmer and a stopword eliminator into your code. Answer again questions a.-e.:
a. Total number of words: 259,908
b. Vocabulary size: 12,836
c. Top 20 words in the ranking (i.e., the words with the highest frequencies):
| # | Word | Total Freq | Absolute Freq (%) |
|---|---|---|---|
| 1 | system | 3,743 | 1.4401249672961203 |
| 2 | agent | 2,692 | 1.0357511119319143 |
| 3 | data | 2,691 | 1.0353663604044507 |
| 4 | inform | 2,395 | 0.9214799082752358 |
| 5 | model | 2,315 | 0.8906997860781507 |
| 6 | paper | 2,246 | 0.8641519306831648 |
| 7 | queri | 1,906 | 0.733336411345553 |
| 8 | user | 1,756 | 0.6756236822260184 |
| 9 | learn | 1,740 | 0.6694676577866014 |
| 10 | algorithm | 1,584 | 0.6094464195022854 |
| 11 | approach | 1,544 | 0.5940563584037428 |
| 12 | problem | 1,543 | 0.5936716068762793 |
| 13 | applic | 1,523 | 0.5859765763270081 |
| 14 | present | 1,507 | 0.579820551887591 |
| 15 | base | 1,487 | 0.5721255213383197 |
| 16 | web | 1,439 | 0.5536574480200687 |
| 17 | databas | 1,424 | 0.5478861751081152 |
| 18 | comput | 1,384 | 0.5324961140095726 |
| 19 | introduc | 1,359 | 0.5228773258229835 |
| 20 | method | 1,223 | 0.4705511180879388 |
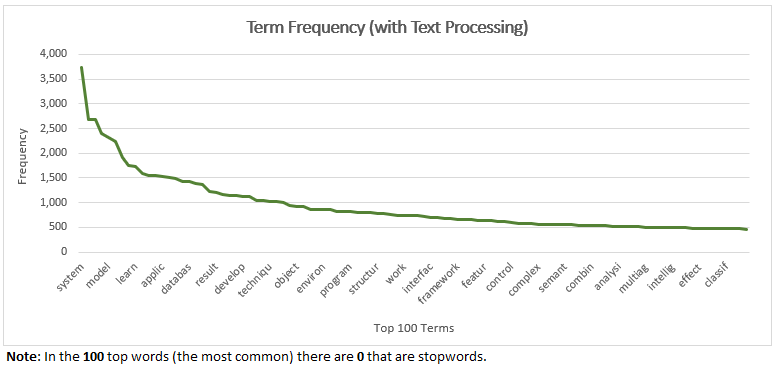
d. List of stop-words contained in the top 20 words: The top 20 words (most common) that are stopwords is: 0
e. The minimum number of unique words accounting for 15% is: 22 which represent the 15.337350139280053 % of the total number of words in the collection.
Q4: Encode each document using the sparse TF-IDF representation:
First 10 examples:
- jeh02simrank - [560:3, 583:2, 642:1, 927:2, 1431:1, 1931:1, 1999:1, 2039:4, 2215:1, 2883:1, 3151:1, 3169:3, 3175:2, 3387:2, 3394:1, 3799:1, 3938:1, 4423:1, 4598:1, 5657:1, 5760:1, 6652:1, 6722:7, 6992:1, 7683:5, 7695:1, 7725:1, 8007:1, 8775:1, 8871:1, 8901:1, 9354:1, 9358:2, 9500:1, 9874:1, 10171:1, 10228:7, 10239:1, 10250:4, 10785:1, 10786:1, 10919:1, 11185:1, 11291:1]
- 265990 - [170:1, 350:1, 558:1, 583:2, 666:1, 713:1, 927:1, 1199:1, 1343:1, 1567:1, 1745:1, 1895:3, 2157:1, 2581:2, 2812:1, 2821:1, 2831:1, 3278:1, 3743:1, 3778:1, 4018:4, 4085:1, 4134:1, 5375:2, 5396:3, 5569:1, 5757:2, 6153:1, 6497:1, 6538:1, 6539:1, 6992:4, 7101:1, 7431:1, 7683:5, 8044:1, 8059:1, 8081:1, 8182:1, 8247:1, 8646:1, 8662:1, 8765:3, 8771:3, 8775:1, 8804:2, 8835:1, 8867:3, 9210:1, 9221:2, 9234:1, 9241:1, 9354:4, 9358:3, 9430:1, 9432:1, 9569:1, 10262:1, 10417:1, 10462:1, 10665:1, 11121:2, 11434:1, 11586:1, 11796:1, 11876:1, 12091:1, 12432:1, 12655:1]
- 502491 - [123:1, 194:1, 248:4, 447:2, 583:1, 835:1, 927:1, 1895:1, 1962:1, 2831:1, 2883:2, 3579:1, 4629:1, 4797:1, 5230:1, 6983:1, 7098:1, 7139:1, 8081:1, 8092:2, 8702:1, 8768:1, 8892:1, 9168:1, 9478:1, 9831:1, 10121:1, 10396:1, 10923:1, 11045:1, 11204:2, 11205:2]
- cummins99language - [433:1, 558:1, 583:1, 758:1, 822:1, 904:1, 927:1, 931:1, 1470:1, 1931:2, 2500:2, 2774:1, 2943:1, 3043:1, 3553:1, 3594:1, 3808:1, 3941:3, 4028:1, 4193:1, 4462:1, 4608:1, 5044:1, 5146:5, 5237:1, 5396:2, 5453:1, 5474:1, 5795:1, 5937:1, 6081:7, 6236:3, 6260:2, 6278:1, 6539:1, 6559:1, 6574:1, 6992:1, 7385:3, 7396:2, 7710:1, 8061:2, 8877:3, 8878:4, 9267:2, 9363:1, 9500:1, 9930:1, 9939:1, 10084:2, 10482:1, 10501:1, 11045:2, 11121:1, 11133:1, 12173:1]
- plaisant99design - [128:1, 134:1, 854:1, 1003:1, 1616:1, 1832:1, 1895:2, 1962:1, 2045:1, 2403:1, 2581:1, 2803:1, 2831:1, 2847:4, 2960:1, 3047:1, 3073:1, 3169:1, 3374:1, 3387:2, 3441:1, 3551:2, 3708:1, 3795:2, 3872:1, 4103:1, 4673:1, 4924:5, 5229:1, 5230:2, 5663:1, 6153:4, 6155:1, 6231:1, 6539:1, 6725:1, 7036:1, 7315:1, 8081:2, 8163:1, 8267:1, 8702:2, 8791:1, 8808:1, 8830:1, 8901:2, 9171:1, 9256:3, 9306:1, 9533:1, 9536:1, 9903:1, 10235:1, 10252:1, 10255:1, 10471:1, 10484:1, 10568:1, 10795:1, 10962:1, 11045:1, 11121:1, 11188:1, 11505:1, 11581:1, 12252:1, 12432:1, 12645:1]
- 489313 - [85:1, 128:1, 248:3, 291:1, 694:1, 726:1, 820:1, 835:1, 927:1, 2150:1, 2152:2, 2241:4, 2700:2, 2740:1, 2812:1, 3110:1, 3160:1, 3533:1, 3596:1, 3708:1, 3831:1, 4135:1, 4332:2, 4341:1, 4748:1, 5229:1, 5296:1, 5396:1, 5544:1, 6554:1, 6725:1, 6786:1, 6992:3, 7139:1, 7362:5, 7379:1, 8081:1, 8155:1, 8156:1, 8572:1, 8600:1, 8702:1, 8791:1, 8890:2, 9164:1, 9166:1, 9831:1, 9958:1, 11045:1, 11185:1, 11434:3, 11454:1, 11875:1, 12134:2, 12179:1]
- roubos00learning - [558:2, 560:1, 583:1, 822:2, 927:3, 1111:1, 1740:1, 1748:6, 1749:2, 2027:1, 2152:1, 2581:4, 2689:2, 2741:1, 2821:1, 2847:1, 2867:1, 2872:1, 2883:1, 3611:1, 3800:1, 3916:1, 3941:1, 4354:4, 4364:1, 5237:1, 5258:2, 5453:1, 5491:1, 5613:2, 5647:1, 5761:1, 6047:1, 6153:1, 6363:1, 6515:1, 6538:1, 6539:1, 6740:1, 6992:3, 8007:1, 8267:1, 8775:2, 8791:1, 8871:1, 8901:1, 9233:1, 9282:1, 9500:2, 9715:3, 9716:2, 9938:1, 10173:1, 10247:1, 10350:1, 10785:1, 10862:1, 10962:1, 11045:3, 11731:1, 12599:1]
- macskassy01intelligent - [23:1, 128:2, 511:1, 560:2, 591:2, 702:2, 822:1, 927:2, 1343:1, 1506:1, 1748:1, 1749:1, 1974:1, 2027:1, 2083:1, 2205:1, 2322:2, 2332:1, 2403:1, 2422:1, 2427:1, 2788:1, 2831:1, 3047:1, 3151:4, 3704:1, 3708:2, 3813:1, 4018:1, 4150:1, 4353:1, 5187:1, 5237:5, 5246:1, 5333:3, 5396:3, 5414:1, 5423:1, 5529:1, 5748:1, 5757:1, 6047:2, 6052:1, 6092:2, 6153:1, 6582:1, 7098:1, 7725:3, 7726:1, 8081:2, 8263:1, 8479:1, 8650:2, 8690:1, 8731:2, 8756:1, 8787:2, 8791:3, 8802:1, 8879:6, 8901:1, 8958:1, 9112:1, 9120:1, 9452:1, 9518:1, 10219:1, 10228:1, 10704:2, 10723:7, 10799:1, 10862:2, 10900:1, 10915:1, 11045:1, 11291:1, 11308:1, 11434:1, 11452:2, 11596:2, 11669:2, 11982:1, 12338:1]
- merz99genetic - [350:4, 393:1, 491:1, 583:1, 659:1, 1055:1, 1095:4, 1238:2, 1979:1, 2039:1, 2440:1, 3676:1, 3795:1, 4028:1, 4214:1, 4433:4, 4853:1, 4868:1, 4894:1, 5078:1, 5174:1, 5303:2, 5502:4, 5647:1, 6092:2, 6193:1, 6333:2, 6663:1, 7665:1, 7914:1, 8081:1, 8702:1, 8775:6, 8820:3, 9001:3, 9135:1, 9500:1, 9903:4, 10156:1, 10171:1, 10173:1, 10239:1, 10252:1, 10306:1, 10350:2, 10430:3, 10915:1, 10944:1, 11025:1, 11074:2, 11283:1, 11361:1, 11434:1, 11885:2, 11949:1, 12173:1, 12192:1]
- kervrann00level - [101:1, 1224:1, 2033:1, 2509:1, 2581:1, 2872:1, 3546:4, 4243:1, 4332:3, 4504:3, 5194:2, 5544:1, 6207:1, 6268:1, 6913:4, 6992:2, 7704:1, 7907:1, 8128:2, 8871:1, 9333:1, 9671:1, 9930:3, 10084:1, 11253:1, 12180:1]
Output files:
- File list output: output/filelist.txt
- Word list output: output/wordlist.txt
- Sparse TF-IDF representation: output/sparse-tf-idf.txt
Conclusions
- TF-IDF is an excellent technique to identify the keywords of each document within a collection.
- Remove stopwords and apply stemming and lematization techniques, helps to filter the list of relevant terms of each document, providing a better entry for the TF-IDF algorithm.
- An inverted index is an excellent and fast data structure to manipulate the obtained keywords by the TF-IDF algorithm.
Authors
- Created By: Andres Segura Tinoco
- Created On: June 9, 2018
License
This project is licensed under the terms of the MIT license.